ONNXRuntime은 Microsoft에서 출시한 추론 프레임워크로, 사용자는 이를 사용하여 ONNX 모델을 매우 편리하게 실행할 수 있음.
ONNXRuntime은 CPU, GPU, TensorRT, DML등 다양한 백엔드를 지원함.
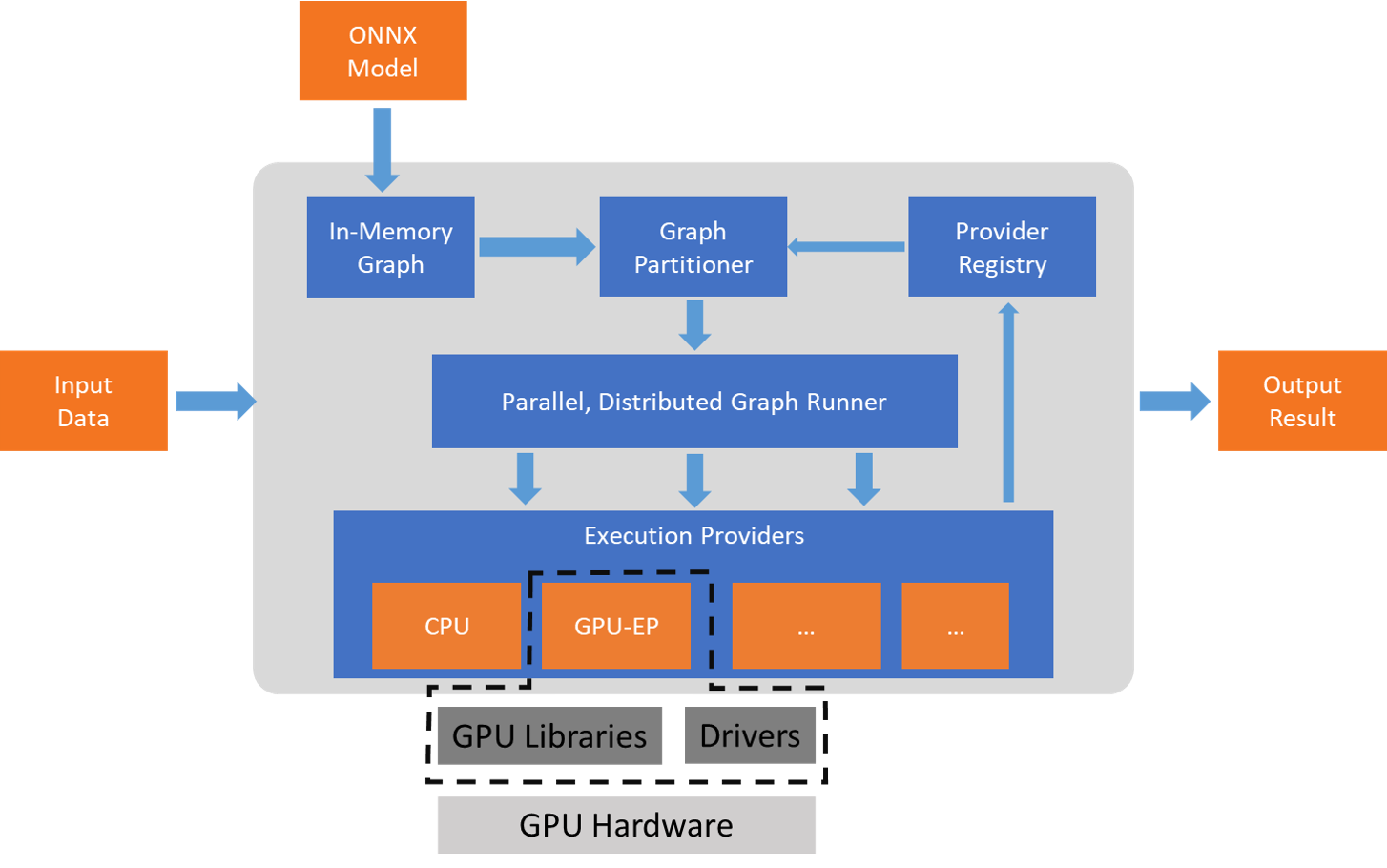
Inference를 위한 ONNX Runtime 작동원리
- 모델 생성/변환
ONNX 형식으로 변환가능한 프레임워크를 사용해 모델 학습 후 ONNX 형식으로 변환
- ONNX Runtime으로 모델 불러오기
- 다른 런타임 구성 또는 하드웨어 가속기를 사용하여 성능 조절(참고)
ONNX Runtime은 모델 그래프에 여러 그래프 최적화를 적용한 다음 사용 가능한 하드웨어별 가속기를 기반으로 하위 그래프로 분할. 핵심 ONNX Runtime의 최적화된 계산 커늘은 성능향상을 제공하고 할당된 하위 그래프는 각 Execution Provider의 추가 가속화를 통해 이점을 얻음.
Training을 위한 ONNX Runtime 작동원리
ONNX Runtime for Pytorch는 ORTModule 클래스 래퍼를 사용하여 자동으로 내보낸 최적화된 ONNX 계산 그래프를 사용하여 훈련 스크립트의 순전파와 역전파를 실행함.
ORT 훈련은 ORT 추론과 같이 그래프 최적화를 사용하여 모델 훈련 가속화를 허용함.
Execution Provider
ONNX Runtime은 Extensible EP(Excution Provider) 프레임워크를 통해 다양한 하드웨어 가속 라이브러리와 함께 작동하여 하드웨어 플랫폼에서 ONNX 모델을 최적으로 실행함.
ONNX Runtime은 Getcapability() 인터페이스를 통해 EP와 함께 작동하여 지원되는 하드웨어에 특정 노드 또는 하위 그래프를 할당함.
실행환경에 사전설치된 EP 라이브러리는 하드웨어에서 ONNX 하위 그래프를 처리하고 실행합니다.
이 아키텍처는 CPU, GPU, FPGA 또는 특수 NPU와 같은 하드웨어 플랫폼에서 심층 신경망의 실행을 최적화하는 데 필수적인 하드웨어별 라이브러리의 세부 정보를 추상화합니다.
지원되는 Execution Providers
| CPU | GPU | IoT/Edge/Mobile | Other |
| Default CPU | NVIDIA CUDA | Intel OpenVINO | Rockchip NPU (preview) |
| Intel DNNL | NVIDIA TensorRT | ARM Compute Library (preview) | Xilinx Vitis-AI (preview) |
| TVM (preview) | DirectML | Android Neural Networks API | Huawei CANN (preview) |
| Intel OpenVINO | AMD MIGraphX | ARM-NN (preview) | |
| XNNPACK | Intel OpenVINO | CoreML (preview) | |
| AMD ROCm | TVM (preview) | ||
| TVM (preview) | Qualcomm SNPE | ||
| XNNPACK |
어떤 Execution Provider가 최고의 퍼포먼스를 보일까?
CUDA(Default GPU) and CPU
ORT의 CPU버전은 ONNX spec의 모든 연산자를 완벽하게 구현할 수 있음.
⇒ ONNX 호환모델이 성공적으로 실행될 수 있음.
BUT, 모든 CUDA 커널이 구현되는 것은 아님.
⇒ 필요에 따라 우선순위가 지정되기 때문.
만약 모델에 CUDA 구현이 필요없는 연산자가 포함되어 있다면 다시 CPU로 대체될 수 있음.
CPU와 GPU 사이를 전환하면 성능에 상당한 영향을 미칠 수 있음.
TensorRT and CUDA
TensorRT와 CUDA는 ONNX Runtime을 위한 별도의 Execution Provider임.
동일한 하드웨어에서 TensorRT가 일반적으로 더 좋은 성능을 제공하지만, 특정 모델과 모델의 연산자가 TensorRT에서 지원될 수 있는지 여부에 따라 다름.
TensorRT가 하위 그래프를 처리할 수 없는 경우 CUDA로 대체됨.
TensorRT/CUDA or DirectML
DirectML은 Windows에서 기계학습을 위한 hardware-accelerated DirectX12라이브러리이며 모든 DirectX12지원장치(Nvidia, Intel, AMD)를 지원함.
⇒ 즉, Windows GPU를 대상으로 하는 경우 TensorRT/CUDA에 비해 DirectML Execute Provider를 사용하는 것이 가장 좋음.
기타
Execution Provider 추가하기
Execution Provider로 ONNX Runtime 패키지 빌드
Reference
https://blog.csdn.net/jiugeshao/article/details/124533956
https://onnxruntime.ai/docs/#onnx-runtime-for-inferencing
- High Performance runtime for ONNX models
- Support full ONNX-ML spec
- Available for Linux, Windows and Mac
- Runs with CPU and GPU, with extensible architecture to plug-in additional hardware accelerators
- Get an INNX model from the zoo model or by converting from various frameworks
- Pytorch으로 개발된 실시간 추론 서비스는 느린데, 이를 ONNX로 개선 가능
⇒ Pytorch 모델을 ONNX으로 변환 후 ONNXruntime을 사용하여 추론 엔진 구축시, 2~3배 정도의 속도향상을 이룰 수 있음.
- TensorRT의 제한점인 Unsupported Operator을 ONNX Runtime을 통해 개선할 수 있음.
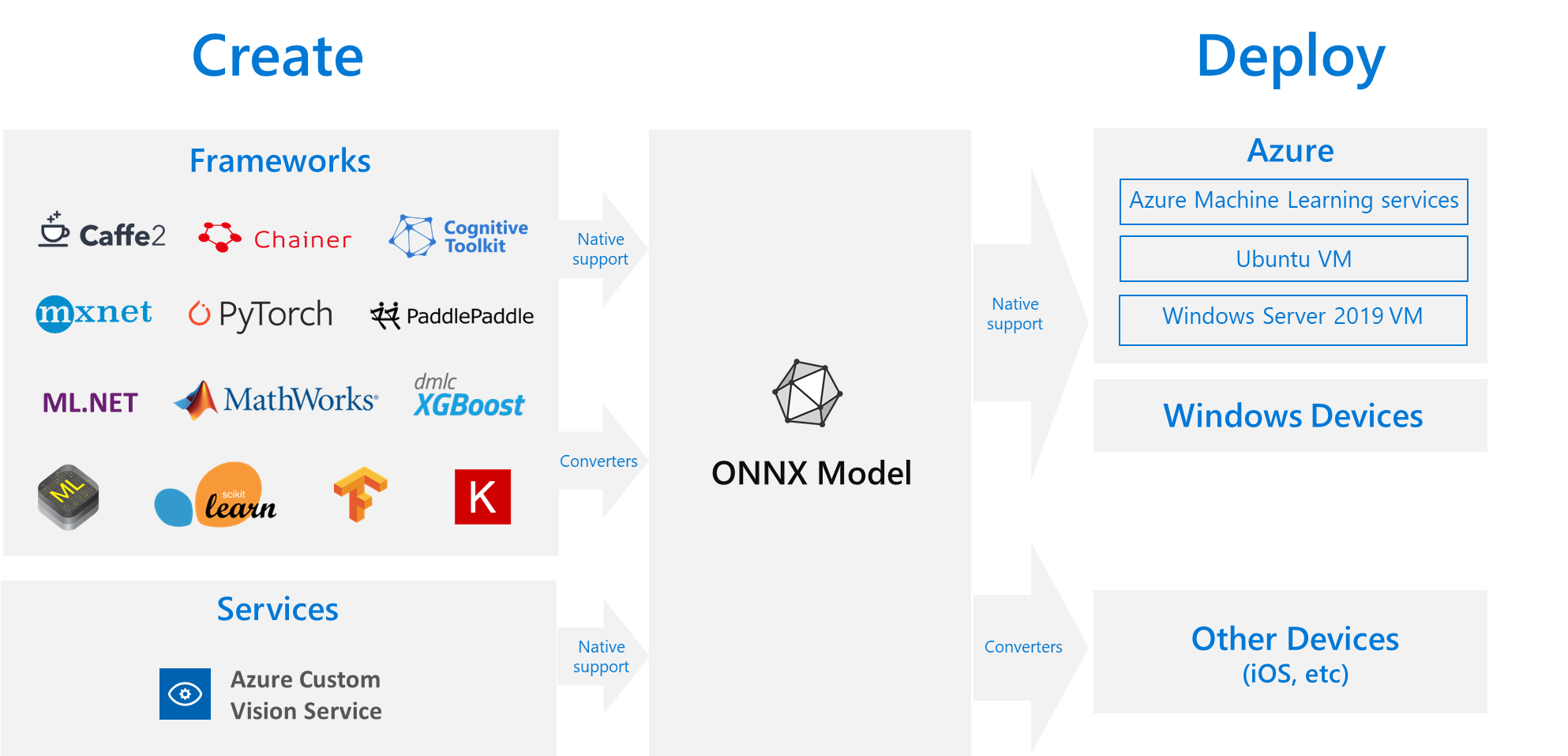
출처 - 마이크로소프트 “ONNX and Azure Machine Learning: Create and accelerate ML models”
Reference
https://velog.io/@hsp/model-inference-with-ONNX
https://medium.com/@may_i/onnx-runtime-high-performance-deep-learning-inference-3a4f95a41c15